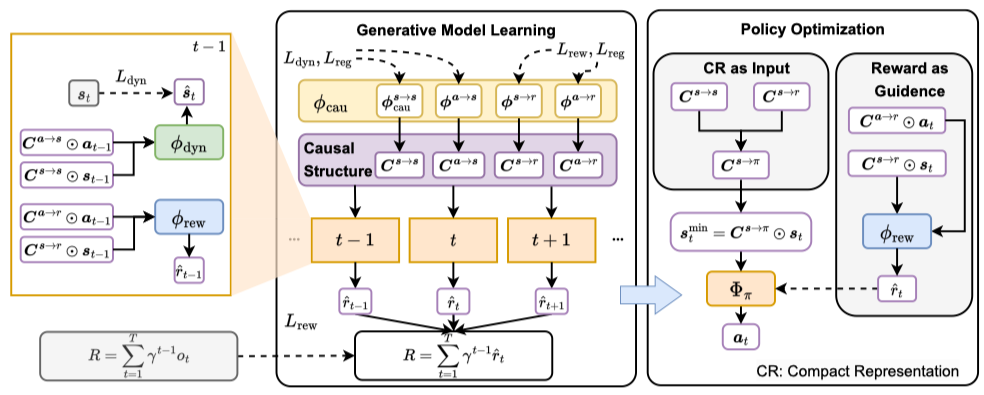
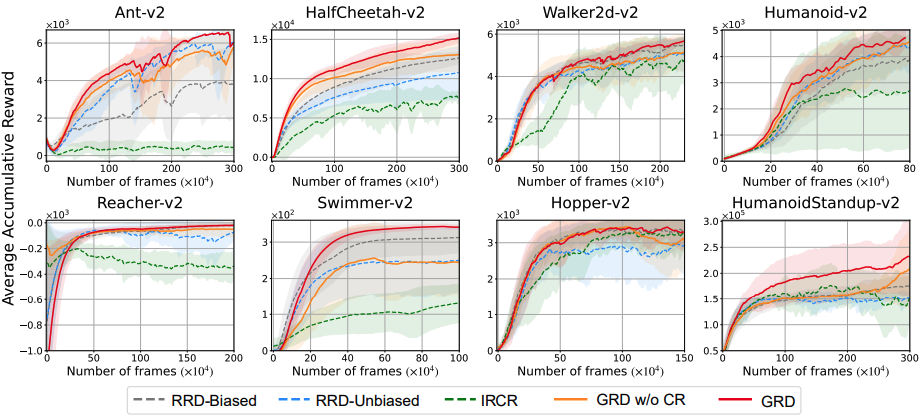
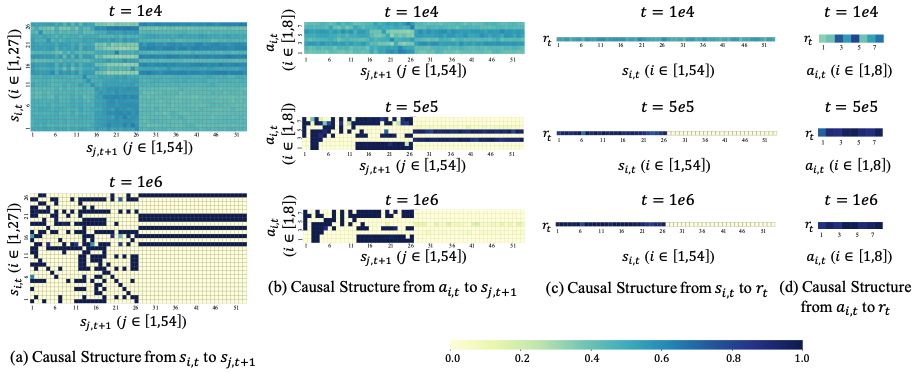
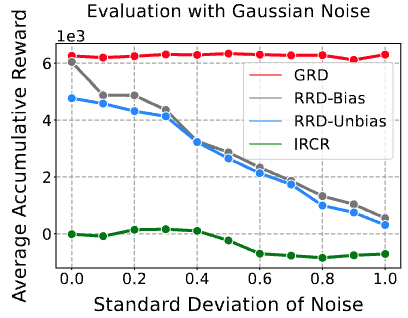
A Causal Reformulation of Reward Redistribution
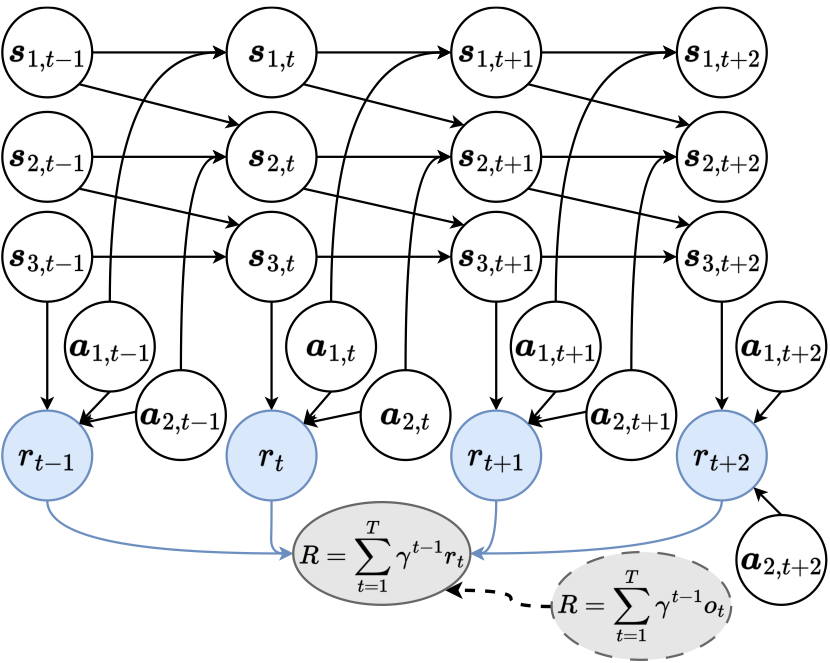
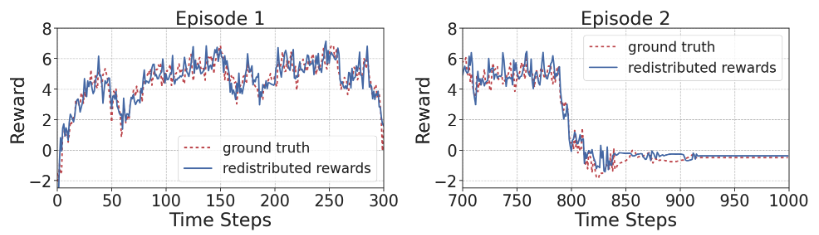
Figure 1 shows the causal relationship among environmental variables. The nodes denote different variables in the MDP environment, i.e., all dimensions of state \(\boldsymbol s_{\cdot, t}\) and action \(\boldsymbol a_{\cdot, {t}}\), Markovian rewards \(r_{t}\) for \(t\in[1, T]\), as well as the long-term return \(R\). For sparse reward settings in RL, the Markovian rewards \(r_t\) are unobservable, which are represented by nodes with blue filling. While considering the return-equivalent assumption in return decomposition, we can observe the trajectory-wise long-term return, \(R\), which equals the discounted sum of delayed reward \(o_t\) and evaluates the performance of the agent within the whole episode. A special case of delayed rewards is in episodic RL, where \(o_{1:T-1} = 0\) and \(o_T \neq 0\).